Спецификация кодировки исходного кода в MSVС++, например gcc "-finput-charset = CharSet"
Я хочу создать несколько примеров программ, которые обрабатывают кодировки, в частности, я хочу
использовать широкие строки, например:
wstring a=L"grüßen";
wstring b=L"שלום עולם!";
wstring c=L"中文";
Потому что это примеры программ.
Это абсолютно тривиально с gcc, который обрабатывает исходный код как кодированный текст UTF-8.
Но простая подборка не работает под MSVC. Я знаю, что могу кодировать их
используя escape-последовательности, но я бы предпочел сохранить их как читаемый текст.
Есть ли какая-либо опция, которую я могу указать как переключатель командной строки для "cl", чтобы
сделать эту работу?
Там есть любой переключатель командной строки, такой как gcc'c -finput-charset
Спасибо,
Если вы не предложите сделать текст естественным для пользователя?
Примечание. добавление спецификации в файл UTF-8 не является опцией, поскольку она становится не компилируемой другими компиляторами.
Примечание2: Мне нужно, чтобы он работал в версии MSVC >= 9 == VS 2008
Реальный ответ: Нет решения
Ответы
Ответ 1
Для тех, кто подписывается на девиз "лучше поздно, чем никогда", Visual Studio 2015 (версия 19 компилятора) теперь поддерживает это.
Новый переключатель командной строки /source-charset позволяет вам указать кодировку набора символов, используемую для интерпретации исходных файлов. Он принимает один параметр, который может быть либо IANA, либо имя набора символов ISO:
/source-charset:utf-8
или десятичный идентификатор конкретной кодовой страницы (которой предшествует точка):
/source-charset:.65001
Официальная документация здесь, а также подробная статья описывая эти новые параметры в блоге команды Visual С++.
Существует также дополнительный /execution-charset switch, который работает точно так же, но контролирует, как генерируются узкие символы и строковые литералы в исполняемом файле. Наконец, есть переключатель быстрого доступа, /utf-8, который устанавливает как /source-charset:utf-8, так и /execution-charset:utf-8.
Эти параметры командной строки несовместимы со старыми директивами #pragma setlocale и #pragma execution-character-set, и они применяются глобально ко всем исходным файлам.
Для пользователей, придерживающихся более старых версий компилятора, лучший вариант - сохранить исходные файлы как UTF-8 с спецификацией (как предложили другие ответы, IDE может это сделать при сохранении). Компилятор автоматически обнаружит это и будет вести себя соответствующим образом. Так же будет GCC, который также принимает спецификацию в начале исходных файлов без удушения до смерти, делая этот подход функционально переносимым.
Ответ 2
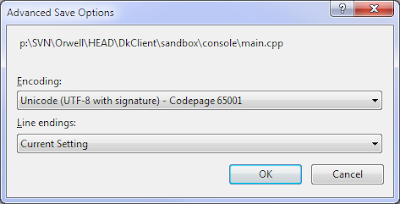
Откройте File->Advances Save Options...
Выберите Unicode(UTF-8 with signature) - Codepage 65001 в комбо-кодировке. Компилятор автоматически использует выбранную кодировку.
![advancedsave.png]()
Согласно Microsoft ответьте здесь:
если вы хотите не-ASCII-символы, тогда "официальный" и переносимый способ получить их - использовать шестнадцатеричную кодировку \u (или\U) (которая, я согласна, просто уродливая и подверженная ошибкам).
Компилятор, столкнувшись с исходным файлом, который не имеет спецификации, компилятор читает впереди определенное расстояние в файле, чтобы увидеть, может ли он обнаруживать любые символы Юникода - он специально ищет UTF-16 и UTF-16BE - если он не находит ни то, значит он предполагает, что он имеет MBCS. Я подозреваю, что в этом случае он возвращается к MBCS, и это то, что вызывает проблему.
Быть явным - это действительно лучше, и поэтому, хотя я знаю, что это не идеальное решение , я бы предложил использовать спецификацию.
Пещеры Джонатана
Команда компилятора Visual С++.
Хорошее решение будет размещать текстовые строки в файлах ресурсов. Это удобно и переносимо. Для управления переводами можно использовать библиотеки локализации, такие как gettext.
Ответ 3
IMHO все исходные файлы С++ должны быть в строгом ASCII. Комментарии могут быть в UTF-8, если редактор поддерживает его.
Это делает код переносимым между платформами, редакторами и системами управления версиями.
Вы можете использовать \u для вставки символов Юникода в широкую строку:
std::wstring str = L"\u20AC123,00"; //€123,00
Ответ 4
Поток, который мы использовали: сохранение файлов как UTF8 - с помощью спецификации, общий ресурс между linux и windows, для linux: предварительная обработка исходных файлов в команде компиляции для удаления спецификации, запуск g++ на промежуточной не-спецификации файл.
Ответ 5
Для VS вы можете использовать:
#pragma setlocale( "[locale-string]" )
В качестве кодировки файла будет использоваться стандартная кодовая страница ANSI по умолчанию.
Но в целом это плохая идея, чтобы жестко закодировать любые видимые пользователем строки в коде.
Храните их в каких-то ресурсах. Хорошо для локализации, простой проверки орфографии и обновления и т.д.