Состояние гонки на x86
Может ли кто-нибудь объяснить это утверждение:
shared variables
x = 0, y = 0
Core 1 Core 2
x = 1; y = 1;
r1 = y; r2 = x;
Как возможно иметь r1 == 0 и r2 == 0 на процессорах x86?
Источник "Язык Concurrency" от Bartosz Milewski.
Ответы
Ответ 1
Проблема может возникнуть из-за оптимизации, включающей переупорядочение инструкций. Другими словами, оба процессора могут назначать r1 и r2 до назначение переменных x и y, если они обнаружат, что это даст лучшую производительность. Это можно решить, добавив барьер памяти, который обеспечит ограничение порядка.
Чтобы процитировать слайдшоу о котором вы упомянули в своем сообщении:
Современные многоядерные/языки разбивают последовательную согласованность.
Что касается архитектуры x86, лучшим ресурсом для чтения является Руководство разработчика программного обеспечения для разработчиков Intel® 64 и IA-32 (глава 8.2 Заказ памяти). В разделах 8.2.1 и 8.2.2 описывается порядок запоминания, реализованный
Intel486, Pentium, Intel Core 2 Duo, Intel Atom, Intel Core Duo, Pentium 4, Intel
Xeon и P6: модель памяти, называемая заказом процессора, в отличие от упорядочения программ (сильного упорядочения) старой архитектуры Intel386 ( где инструкции чтения и записи всегда выдавались в том порядке, в котором они появлялись в потоке команд).
В руководстве описаны многие гарантии заказа модели памяти для заказа процессора (такие как Loads не переупорядочиваются с другими нагрузками, магазины не переупорядочиваются с другими магазинами, магазины не переупорядочены с более старыми нагрузками и т.д.), но также описывает разрешенное правило переупорядочения, которое вызывает состояние гонки в сообщении OP:
8.2.3.4 Нагрузки могут быть переупорядочены с более ранними магазинами до разных Местоположение
С другой стороны, если исходный порядок инструкций был переключен:
shared variables
x = 0, y = 0
Core 1 Core 2
r1 = y; r2 = x;
x = 1; y = 1;
В этом случае процессор гарантирует, что ситуация r1 = 1 и r2 = 1 не разрешена (из-за 8.2.3.3. Резервирование магазинов не выполняется с гарантией более ранней загрузки), что означает, что эти инструкции никогда не будут переупорядочены в отдельных ядрах.
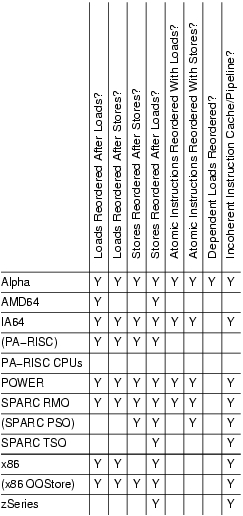
Чтобы сравнить это с различными архитектурами, ознакомьтесь с этой статьей: Заказ памяти в современных микропроцессорах (это изображение). Вы можете видеть, что Itanium (IA-64) делает еще большее переупорядочение, чем архитектура IA-32.
Ответ 2
На процессорах с более слабой моделью согласованности памяти (например, SPARC, PowerPC, Itanium, ARM и т.д.) вышеуказанное условие может иметь место из-за отсутствия принудительной кэш-когерентности при записи без явной инструкции барьера памяти. Таким образом, в основном Core1 видит запись на x до y, а Core2 видит запись на y до x. В этом случае не требуется полная инструкция по заграждению... в основном вам нужно будет только принудительно применять семантику записи или выпуска с этим сценарием, чтобы все записи были зафиксированы и видимы для всех процессоров, прежде чем чтение будет проходить по тем переменным, которые были написано на. Архитектуры процессоров с сильными моделями согласованности памяти, такими как x86, обычно делают это ненужным, но, как отмечает Гроо, сам компилятор может переупорядочить операции. Вы можете использовать ключевое слово volatile в C и С++, чтобы предотвратить переупорядочение операций компилятором в заданном потоке. Это не означает, что volatile создаст потокобезопасный код, который управляет видимостью чтения и записи между потоками... для этого потребуется барьер памяти. Таким образом, хотя использование volatile может по-прежнему создавать небезопасный потоковый код, в пределах данного потока он будет обеспечивать последовательную согласованность на уровне стандартного машинного кода.
Ответ 3
Проблема заключается в том, что ни один нить не обеспечивает никакого упорядочения между двумя его операторами, поскольку они не являются взаимозависимыми.
-
Компилятор знает, что x и y не являются псевдонимами, и поэтому не требуется заказывать операции.
-
ЦП знает, что x и y не являются псевдонимом, поэтому он может изменять порядок их скорости. Хорошим примером того, когда это происходит, является то, что CPU обнаруживает возможность комбинировать запись. Он может объединить одну запись с другой, если она может сделать это, не нарушая ее модель когерентности.
Взаимная зависимость выглядит странно, но она не отличается от других условий гонки. Прямо писать код с разделяемой памятью довольно сложно, и поэтому были разработаны параллельные языки и параллельные рамки для передачи сообщений, чтобы изолировать параллельные опасности до небольшого ядра и удалить опасности из самих приложений.
{kind=link}