Как сборка выполняет передачу параметров: по значению, ссылке, указателю для разных типов/массивов?
В попытке взглянуть на это, я написал этот простой код, где я просто создал переменные разных типов и передал их в функцию по значению, по ссылке и по указателю:
int i = 1;
char c = 'a';
int* p = &i;
float f = 1.1;
TestClass tc; // has 2 private data members: int i = 1 and int j = 2
тела функций остались пустыми, потому что я просто смотрю, как передаются параметры.
passByValue(i, c, p, f, tc);
passByReference(i, c, p, f, tc);
passByPointer(&i, &c, &p, &f, &tc);
хотел посмотреть, как это отличается для массива, а также как параметры доступа к ним.
int numbers[] = {1, 2, 3};
passArray(numbers);
монтаж:
passByValue(i, c, p, f, tc)
mov EAX, DWORD PTR [EBP - 16]
mov DL, BYTE PTR [EBP - 17]
mov ECX, DWORD PTR [EBP - 24]
movss XMM0, DWORD PTR [EBP - 28]
mov ESI, DWORD PTR [EBP - 40]
mov DWORD PTR [EBP - 48], ESI
mov ESI, DWORD PTR [EBP - 36]
mov DWORD PTR [EBP - 44], ESI
lea ESI, DWORD PTR [EBP - 48]
mov DWORD PTR [ESP], EAX
movsx EAX, DL
mov DWORD PTR [ESP + 4], EAX
mov DWORD PTR [ESP + 8], ECX
movss DWORD PTR [ESP + 12], XMM0
mov EAX, DWORD PTR [ESI]
mov DWORD PTR [ESP + 16], EAX
mov EAX, DWORD PTR [ESI + 4]
mov DWORD PTR [ESP + 20], EAX
call _Z11passByValueicPif9TestClass
passByReference(i, c, p, f, tc)
lea EAX, DWORD PTR [EBP - 16]
lea ECX, DWORD PTR [EBP - 17]
lea ESI, DWORD PTR [EBP - 24]
lea EDI, DWORD PTR [EBP - 28]
lea EBX, DWORD PTR [EBP - 40]
mov DWORD PTR [ESP], EAX
mov DWORD PTR [ESP + 4], ECX
mov DWORD PTR [ESP + 8], ESI
mov DWORD PTR [ESP + 12], EDI
mov DWORD PTR [ESP + 16], EBX
call _Z15passByReferenceRiRcRPiRfR9TestClass
passByPointer(&i, &c, &p, &f, &tc)
lea EAX, DWORD PTR [EBP - 16]
lea ECX, DWORD PTR [EBP - 17]
lea ESI, DWORD PTR [EBP - 24]
lea EDI, DWORD PTR [EBP - 28]
lea EBX, DWORD PTR [EBP - 40]
mov DWORD PTR [ESP], EAX
mov DWORD PTR [ESP + 4], ECX
mov DWORD PTR [ESP + 8], ESI
mov DWORD PTR [ESP + 12], EDI
mov DWORD PTR [ESP + 16], EBX
call _Z13passByPointerPiPcPS_PfP9TestClass
passArray(numbers)
mov EAX, .L_ZZ4mainE7numbers
mov DWORD PTR [EBP - 60], EAX
mov EAX, .L_ZZ4mainE7numbers+4
mov DWORD PTR [EBP - 56], EAX
mov EAX, .L_ZZ4mainE7numbers+8
mov DWORD PTR [EBP - 52], EAX
lea EAX, DWORD PTR [EBP - 60]
mov DWORD PTR [ESP], EAX
call _Z9passArrayPi
// parameter access
push EAX
mov EAX, DWORD PTR [ESP + 8]
mov DWORD PTR [ESP], EAX
pop EAX
Я предполагаю, что я смотрю на правильную сборку, связанную с передачей параметра, потому что в конце каждого из них есть вызовы!
Но из-за моих очень ограниченных знаний об собраниях я не могу сказать, что происходит здесь. Я узнал о конвенции ccall, поэтому я предполагаю, что что-то происходит, что связано с сохранением регистров, сохраненных вызывающим абонентом, а затем путем нажатия параметров в стек. Из-за этого я ожидаю, что все вещи загрузятся в регистры и "нажимают" всюду, но не имеют представления о том, что происходит с mov и lea s. Кроме того, я не знаю, что такое DWORD PTR.
Я только узнал о регистрах: eax, ebx, ecx, edx, esi, edi, esp и ebp, поэтому просмотр чего-то вроде XMM0 или DL просто смущает меня. Я думаю, имеет смысл видеть lea когда дело доходит до передачи по ссылке/указателю, потому что они используют адреса памяти, но я не могу сказать, что происходит. Когда дело доходит до передачи по значению, кажется, что существует множество инструкций, поэтому это может быть связано с копированием значения в регистры. Не знаю, когда дело доходит до того, как массивы передаются и доступны как параметры.
Если бы кто-то мог объяснить общее представление о том, что происходит с каждым блоком сборки, я бы очень признателен.
Ответы
Ответ 1
Использование регистров CPU для передачи аргументов выполняется быстрее, чем использование памяти, то есть стека. Однако в ЦПУ имеется ограниченное количество регистров (особенно в x86-совместимых ЦП), поэтому, когда функция имеет много параметров, тогда стек используется вместо регистров процессора. В вашем случае есть 5 аргументов функции, поэтому компилятор использует стек для аргументов вместо регистров.
В принципе, компиляторы могут использовать push команды для толкания аргументов для стека до фактического call функции, но многие компиляторы (включая gnu c++) используют mov для толкания аргументов для стека. Этот способ удобен, так как он не изменяет регистр ESP (верхняя часть стека) в части кода, вызывающей функцию.
В случае, если значения passByValue(i, c, p, f, tc) помещаются в стек. Вы можете увидеть много команд mov из ячейки памяти в регистр и из регистра в соответствующее место стека. Причиной этого является то, что сборка x86 запрещает прямое перемещение из одного места памяти в другое (исключение - movs который перемещает значения из одного массива (или строки по вашему желанию) в другой).
В случае passByReference(i, c, p, f, tc) вы можете увидеть много инструкций 5 lea, которые копируют адреса аргументов в регистры CPU, и эти значения регистров переносятся в стек.
Случай passByPointer(&i, &c, &p, &f, &tc) аналогичен passByValue(i, c, p, f, tc). Внутри, на уровне сборки, по ссылке используются указатели, а на более высоком уровне c++, программисту не нужно явно использовать операторы & и * для ссылок.
После того, как параметры перемещаются в стек, выдается call, который подталкивает указатель инструкции EIP к стеку перед передачей выполнения программы в подпрограмму. Все moves параметров к учетной записи стека для следующего EIP в стеке после команды call.
Ответ 2
Там слишком много в вашем примере выше, чтобы вскрыть все из них. Вместо этого я просто passByValue поскольку это кажется самым интересным. Впоследствии вы должны быть в состоянии выяснить остальное.
Прежде всего, некоторые важные моменты, которые следует учитывать при изучении разборки, чтобы вы не потерялись полностью в море кода:
- Нет никаких инструкций по прямой копированию данных из одного места памяти в другое место памяти. например.
mov [ebp - 44], [ebp - 36] не является юридической инструкцией. Для хранения данных сначала требуется промежуточный регистр, а затем копируется в память. - Оператор скобки
[] в сочетании с средством mov для доступа к данным из вычисленного адреса памяти. Это аналогично дешифрованию указателя в C/C++. - Когда вы видите
lea x, [y] который обычно означает вычисляемый адрес y и сохраняет в x. Это аналогично адресу адреса переменной в C/C++. - Данные и объекты, которые необходимо скопировать, но слишком велики, чтобы вписаться в регистр, копируются в стек в куклу. IOW, он скопирует собственное машинное слово за раз, пока не будут скопированы все байты, представляющие объект/данные. Обычно это означает, что 4 или 8 байтов на современных процессорах.
- Компилятор обычно будет чередовать инструкции вместе, чтобы поддерживать занятость в процессоре и минимизировать киоски. Хорошо для эффективности кода, но плохо, если вы пытаетесь понять разборку.
С учетом вышеизложенного вызов функции passByValue перестраивается немного, чтобы сделать его более понятным:
.define arg1 esp
.define arg2 esp + 4
.define arg3 esp + 8
.define arg4 esp + 12
.define arg5.1 esp + 16
.define arg5.2 esp + 20
; copy first parameter
mov EAX, [EBP - 16]
mov [arg1], EAX
; copy second parameter
mov DL, [EBP - 17]
movsx EAX, DL
mov [arg2], EAX
; copy third
mov ECX, [EBP - 24]
mov [arg3], ECX
; copy fourth
movss XMM0, DWORD PTR [EBP - 28]
movss DWORD PTR [arg4], XMM0
; intermediate copy of TestClass?
mov ESI, [EBP - 40]
mov [EBP - 48], ESI
mov ESI, [EBP - 36]
mov [EBP - 44], ESI
;copy fifth
lea ESI, [EBP - 48]
mov EAX, [ESI]
mov [arg5.1], EAX
mov EAX, [ESI + 4]
mov [arg5.2], EAX
call passByValue(int, char, int*, float, TestClass)
Вышеприведенный код не имеет отношения, а смещение команд отменено, чтобы дать понять, что на самом деле происходит, но некоторые все еще требуют объяснения. Во-первых, символ signed и имеет размер по одному байту. Инструкции здесь:
; copy second parameter
mov DL, [EBP - 17]
movsx EAX, DL
mov [arg2], EAX
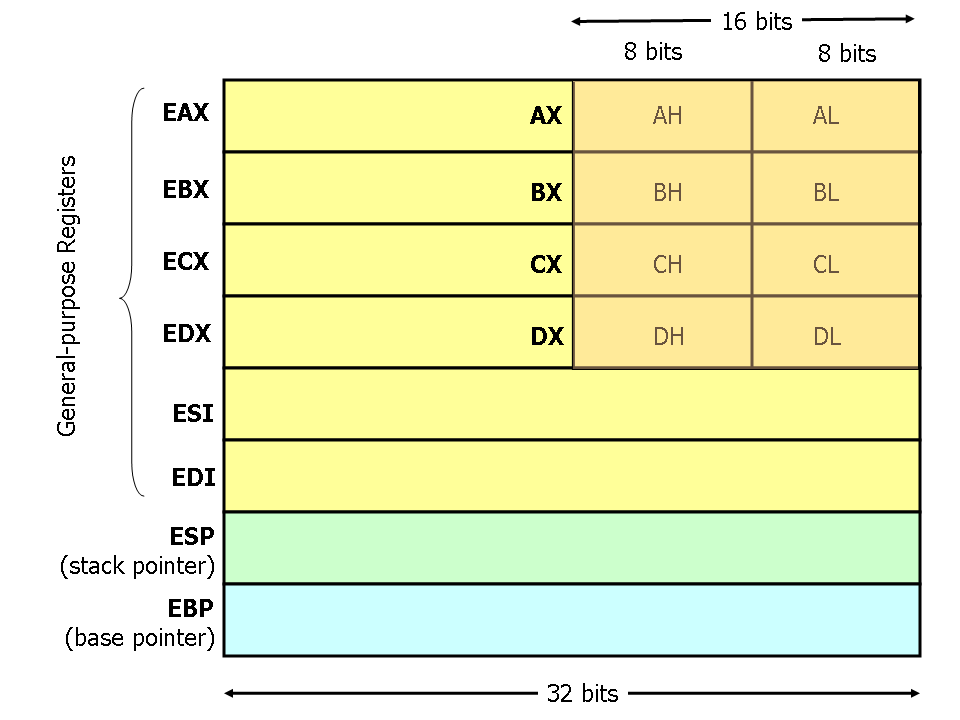
читает байт из [ebp - 17] (где-то в стеке) и сохраняет его в младший первый байт edx. Этот байт затем копируется в eax с помощью расширенного перемещения. Полное 32-битное значение в eax, наконец, копируется в стек, доступ к passByValue может получить passByValue. Если вам нужна более подробная информация, см. Схему реестров.
Четвертый аргумент:
movss XMM0, DWORD PTR [EBP - 28]
movss DWORD PTR [arg4], XMM0
Использует команду SSE movss для копирования значения с плавающей точкой из стека в регистр xmm0. Вкратце, инструкции SSE позволяют выполнять одну и ту же операцию на нескольких фрагментах данных одновременно, но здесь компилятор использует ее как промежуточное хранилище для копирования значений с плавающей запятой в стеке.
Последний аргумент:
; copy intermediate copy of TestClass?
mov ESI, [EBP - 40]
mov [EBP - 48], ESI
mov ESI, [EBP - 36]
mov [EBP - 44], ESI
соответствует TestClass. По-видимому, этот класс имеет размер 8 байтов, расположенный в стеке от [ebp - 40] до [ebp - 33]. Класс здесь копируется по 4 байта за раз, так как объект не может вписаться в один регистр.
Вот что выглядит примерно так: перед call passByValue:
lower addr esp => int:arg1 <--.
esp + 4 char:arg2 |
esp + 8 int*:arg3 | copies passed
esp + 12 float:arg4 | to 'passByValue'
esp + 16 TestClass:arg5.1 |
esp + 20 TestClass:arg5.2 <--.
...
...
ebp - 48 TestClass:arg5.1 <-- intermediate copy of
ebp - 44 TestClass:arg5.2 <-- TestClass?
ebp - 40 original TestClass:arg5.1
ebp - 36 original TestClass:arg5.2
...
ebp - 28 original arg4 <--.
ebp - 24 original arg3 | original (local?) variables
ebp - 20 original arg2 | from calling function
ebp - 16 original arg1 <--.
...
higher addr ebp prev frame
Ответ 3
То, что вы ищете, - это соглашения ABI. Различные платформы имеют разные соглашения. например, Windows на x86-64 имеет разные соглашения, чем Unix/Linux на x86-64.
http://www.agner.org/optimize/ имеет документ-соглашения о вызовах, описывающий различные для x86/amd64.
Вы можете писать код в ASM, который делает все, что угодно, но если вы хотите вызвать другие функции и вызываться ими, тогда передайте параметры/возвращаемые значения в соответствии с ABI.
Полезно было бы использовать вспомогательную функцию внутреннего использования, которая не использует стандартный ABI, но вместо этого использует значения в регистрах, которые вызывающая функция выделяет в них. Это esp. вероятно, если вы пишете основную программу в чем-то, отличном от ASM, с небольшой частью в ASM. Тогда часть asm должна заботиться только о том, чтобы быть переносимой в системы с различными ABI для вызова из основной программы, а не для собственных внутренних компонентов.
{kind=link}