Инкрементный алгоритм k-core
Вычисление k-core графика путем итеративной обрезки вершин достаточно просто. Тем не менее, для моего приложения я хотел бы иметь возможность добавлять вершины к стартовому графику и получать обновленное ядро без необходимости пересчитывать все k-ядро с нуля. Есть ли надежный алгоритм, который может использовать работу, выполненную в предыдущих итерациях?
Для любопытных k-ядро используется в качестве этапа предварительной обработки в алгоритме поиска клики. Любые клики размером 5 гарантированы как часть 4-ядро графа. В моем наборе данных 4-ядро намного меньше, чем весь график, так что грубая задержка его оттуда может быть приемлемой. Поэтапное добавление вершин позволяет алгоритму работать с максимально возможным набором данных. Мой набор вершин бесконечен и упорядочен (простые числа), но я забочусь только о самой низкой пронумерованной клике.
Edit:
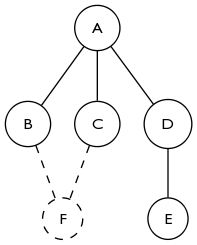
Размышляя об этом еще немного, основанном на ответе akappa, обнаружение создания цикла действительно критично. На приведенном ниже графике 2-ядро пустое до добавления F. Добавление F не меняет степень A, но все равно добавляет A к 2-ядерному ядру. Легко расширить это, чтобы увидеть, как закрытие цикла любого размера приведет к тому, что все вершины будут одновременно присоединяться к 2-ядерному.
Добавление вершины может влиять на coreness вершин на любом расстоянии, но, возможно, это слишком сильно фокусируется на худшем случае.
![A -- B; A -- C; A -- D -- E; B -- F; C -- F;]()
Ответы
Ответ 1
Мне кажется, что алгоритм для инкрементного вычисления k-ядра, основанный на локальном исследовании графика, вместо "глобальной" итеративной обрезки, потребует инкрементного обнаружения цикла, чтобы увидеть, какие ребра могут внести вклад в ввод вершина в k-ядре, что является трудной проблемой.
Я думаю, что самое лучшее, что вы можете сделать, это перекомпилировать алгоритм k-core на каждом проходе, просто удалив из графика вершины, которые уже находятся в k-core и инициализируются, в вершине карты → "k- ядро смежных вершин", число смежных вершин, которые уже находятся в k-ядре.
Ответ 2
Это сложная проблема, но определенно не NP-Hard. Насколько я знаю, в академических кругах нет общих решений по инкрементному обновлению К-ядер с любым числом К. Но следующие две статьи, безусловно, достойны чтения:
[1] Извлечение анализа и визуализации треугольников K-Core Motifs в сетях. http://www.cse.ohio-state.edu/~zhangya/ICDE12_conf_full_179.pdf
[2] Потоковые алгоритмы для разложения k-ядер. http://www.cse.ohio-state.edu/~sariyuce/file/Publications_files/VLDB13.pdf
Они появляются на ведущих конференциях в области управления данными, поэтому методология должна быть надежной.
Ответ 3
Быстрая идея:
Вы можете сохранить историю в списке L, т.е. Сохранить порядок, в котором удалены узлы. Всякий раз, когда вы добавляете новый node v, начинайте с первого node w в L, который смежён с v. Затем просто пройдите оставшиеся узлы в L из w в линейном порядке. (И протестируйте node v, а также, возможно, добавьте его в L.)