Ответ 1
на самом деле это невозможно сделать с помощью регулярных выражений, поскольку регулярные выражения выражают язык, определяемый грамматикой regular, которая может быть решена с помощью не конечного детерминированного автомата, где согласование представлено состояниями; то для соответствия вложенным скобкам вам нужно будет иметь возможность сопоставить бесконечное число скобок и затем иметь автомат с бесконечным числом состояний.
Чтобы справиться с этим, мы используем то, что называется push-down automaton, которое используется для определения грамматики контекстной свободной.
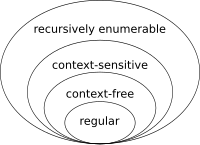
Итак, если ваше регулярное выражение не совпадает с вложенной скобкой, это потому, что оно выражает следующий автомат и ничего не соответствует вашему вводу:

В качестве справочной информации ознакомьтесь с курсами MIT по теме:
- http://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-045j-automata-computability-and-complexity-spring-2011/lecture-notes/MIT6_045JS11_lec04.pdf
- http://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-005-elements-of-software-construction-fall-2011/lecture-notes/MIT6_005F11_lec05.pdf
- http://www.saylor.org/site/wp-content/uploads/2012/01/CS304-2.1-MIT.pdf
Итак, одним из способов эффективного анализа вашей строки является построение грамматики для вложенных скобок (сначала pip install pyparsing):
>>> import pyparsing
>>> strings = pyparsing.Word(pyparsing.alphanums)
>>> parens = pyparsing.nestedExpr( '(', ')', content=strings)
>>> parens.parseString('(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))').asList()
[['NP', ['NNP', 'Hoi'], ['NN', 'Hallo'], ['NN', 'Hey'], ['NNP', ['NN', 'Ciao'], ['NN', 'Adios']]]]
N.B.: существует несколько движков регулярных выражений, которые реализуют вложенные скобки с использованием нажатия. По умолчанию python re не является одним из них, но существует альтернативный механизм, называемый regex (pip install regex), который может do recursive matching (что делает контекст re engine свободным), cf этот фрагмент кода:
>>> import regex
>>> res = regex.search(r'(?<rec>\((?:[^()]++|(?&rec))*\))', '(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))')
>>> res.captures('rec')
['(NNP Hoi)', '(NN Hallo)', '(NN Hey)', '(NN Ciao)', '(NN Adios)', '(NNP (NN Ciao) (NN Adios))', '(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))']