Маскирование переменной длины с помощью preg_replace
Я маскирую все символы между одинарными кавычками (включительно) внутри строки, используя preg_replace_callback(). Но я хотел бы использовать preg_replace(), если это возможно, но не смог понять это. Любая помощь будет оценена.
Это то, что я использую preg_replace_callback(), который производит правильный вывод:
function maskCallback( $matches ) {
return str_repeat( '-', strlen( $matches[0] ) );
}
function maskString( $str ) {
return preg_replace_callback( "('.*?')", 'maskCallback', $str );
}
$str = "TEST 'replace''me' ok 'me too'";
echo $str,"\n";
echo $maskString( $str ),"\n";
Выход:
TEST 'replace''me' ok 'me too'
TEST ------------- ok --------
Я попытался использовать:
preg_replace( "/('.*?')/", '-', $str );
но штрихи потребляются, например:
TEST -- ok -
Все, что я пробовал, тоже не работает. (Я, очевидно, не специалист по регулярному выражению.) Можно ли это сделать? Если да, то как?
Ответы
Ответ 1
Да, вы можете это сделать (при условии, что кавычки сбалансированы):
$str = "TEST 'replace''me' ok 'me too'";
$pattern = "~[^'](?=[^']*(?:'[^']*'[^']*)*+'[^']*\z)|'~";
$result = preg_replace($pattern, '-', $str);
Идея такова: вы можете заменить символ, если это цитата, или если за ним следует нечетное число кавычек.
Без кавычек:
$pattern = "~(?:(?!\A)\G|(?:(?!\G)|\A)'\K)[^']~";
$result = preg_replace($pattern, '-', $str);
Шаблон будет соответствовать символу только в том случае, если он смежн к совпадению с прецедентом (другими словами, когда он сразу после последнего совпадения) или когда ему предшествует цитата, которая не соприкасается с совпадением прецедентов.
\G - это позиция после последнего совпадения (в начале это начало строки)
подробнее:
~ # pattern delimiter
(?: # non capturing group: describe the two possibilities
# before the target character
(?!\A)\G # at the position in the string after the last match
# the negative lookbehind ensure that this is not the start
# of the string
| # OR
(?: # (to ensure that the quote is a not a closing quote)
(?!\G) # not contiguous to a precedent match
| # OR
\A # at the start of the string
)
' # the opening quote
\K # remove all precedent characters from the match result
# (only one quote here)
)
[^'] # a character that is not a quote
~
Обратите внимание, что поскольку заключительная цитата не соответствует шаблону, следующие символы, которые не являются кавычками, не могут быть сопоставлены, потому что совпадение не существует.
EDIT:
Способ (*SKIP)(*FAIL):
Вместо того, чтобы проверять, не является ли одинарная кавычка закрывающей цитатой с (?:(?!\G)|\A)', как в шаблоне прецедента, вы можете разбить смежность совпадения при закрытии кавычек с помощью контрольных глаголов backtracking (*SKIP) и (*FAIL) (Это может быть сократите до (*F)).
$pattern = "~(?:(?!\A)\G|')(?:'(*SKIP)(*F)|\K[^'])~";
$result = preg_replace($pattern, '-', $str);
Так как шаблон не срабатывает при каждом закрытии кавычек, следующие символы не будут сопоставляться до следующей вводной цитаты.
Паттерн может быть более эффективным, например:
$pattern = "~(?:\G(?!\A)(?:'(*SKIP)(*F))?|'\K)[^']~";
(Вы также можете использовать (*PRUNE) вместо (*SKIP).)
Ответ 2
Короткий ответ: возможно!!!
Используйте следующий шаблон
' # Match a single quote
(?= # Positive lookahead, this basically makes sure there is an odd number of single quotes ahead in this line
(?:(?:[^'\r\n]*'){2})* # Match anything except single quote or newlines zero or more times followed by a single quote, repeat this twice and repeat this whole process zero or more times (basically a pair of single quotes)
(?:[^'\r\n]*'[^'\r\n]*(?:\r?\n|$)) # You guessed, this is to match a single quote until the end of line
)
| # or
\G(?<!^) # Preceding contiguous match (not beginning of line)
[^'] # Match anything that not a single quote
(?= # Same as above
(?:(?:[^'\r\n]*'){2})* # Same as above
(?:[^'\r\n]*'[^'\r\n]*(?:\r?\n|$)) # Same as above
)
|
\G(?<!^) # Preceding contiguous match (not beginning of line)
' # Match a single quote
Обязательно используйте модификатор m.
Онлайн-демонстрация.
Длинный ответ: это боль:)
Если не только вы, но и вся ваша команда любят регулярное выражение, вы можете подумать об использовании этого регулярного выражения, но помните, что это безумие и довольно сложно понять для новичков. Также читаемость всегда (почти) всегда первая.
Я сломаю идею того, как я написал такое регулярное выражение:
1) Сначала нам нужно знать, что мы действительно хотим заменить, мы хотим заменить каждый символ (включая одинарные кавычки) между двумя одинарными кавычками с дефисом.
2) Если мы собираемся использовать preg_replace(), это означает, что наш шаблон должен каждый раз соответствовать одному символу.
3) Итак, первый шаг будет очевиден: '.
4) Мы будем использовать \G, что означает начало начала строки или смежного символа, который мы сопоставляли ранее. Возьмем этот простой пример ~a|\Gb~. Это будет соответствовать a или b, если оно в начале или b, если предыдущее совпадение было a. См. Эту демонстрацию .
5) Мы не хотим иметь ничего общего с началом строки. Поэтому мы будем использовать \G(?<!^).
6) Теперь нам нужно сопоставить все, что не является ни одной цитатой ~'|\G(?<!^)[^']~.
7) Теперь начинается настоящая боль, откуда мы знаем, что вышеприведенный шаблон не будет соответствовать c в 'ab'c? Ну, это нужно, нам нужно подсчитать одиночные кавычки...
Обозначим:
a 'bcd' efg 'hij'
^ It will match this first
^^^ Then it will match these individually with \G(?<!^)[^']
^ It will match since we're matching single quotes without checking anything
^^^^^ And it will continue to match ...
То, что мы хотим, может быть сделано в этих трех правилах:
a 'bcd' efg 'hij'
1 ^ Match a single quote only if there is an odd number of single quotes ahead
2 ^^^ Match individually those characters only if there is an odd number of single quotes ahead
3 ^ Match a single quote only if there was a match before this character
8) Проверка наличия нечетного числа одинарных кавычек может быть выполнена, если мы знаем, как соответствовать четному числу:
(?: # non-capturing group
(?: # non-capturing group
[^'\r\n]* # Match anything that not a single quote or newline, zero or more times
' # Match a single quote
){2} # Repeat 2 times (We'll be matching 2 single quotes)
)* # Repeat all this zero or more times. So we match 0, 2, 4, 6 ... single quotes
9) Нечетное число было бы легко сейчас, нам просто нужно добавить:
(?:
[^'\r\n]* # Match anything that not a single quote or newline, zero or more times
' # Match a single quote
[^'\r\n]* # Match anything that not a single quote or newline, zero or more times
(?:\r?\n|$) # End of line
)
10). Слияние выше в одном окне:
(?=
(?: # non-capturing group
(?: # non-capturing group
[^'\r\n]* # Match anything that not a single quote or newline, zero or more times
' # Match a single quote
){2} # Repeat 2 times (We'll be matching 2 single quotes)
)* # Repeat all this zero or more times. So we match 0, 2, 4, 6 ... single quotes
(?:
[^'\r\n]* # Match anything that not a single quote or newline, zero or more times
' # Match a single quote
[^'\r\n]* # Match anything that not a single quote or newline, zero or more times
(?:\r?\n|$) # End of line
)
)
11) Теперь нам нужно объединить все 3 правила, которые мы определили ранее:
~ # A modifier
#################################### Rule 1 ####################################
' # A single quote
(?= # Lookahead to make sure there is an odd number of single quotes ahead
(?: # non-capturing group
(?: # non-capturing group
[^'\r\n]* # Match anything that not a single quote or newline, zero or more times
' # Match a single quote
){2} # Repeat 2 times (We'll be matching 2 single quotes)
)* # Repeat all this zero or more times. So we match 0, 2, 4, 6 ... single quotes
(?:
[^'\r\n]* # Match anything that not a single quote or newline, zero or more times
' # Match a single quote
[^'\r\n]* # Match anything that not a single quote or newline, zero or more times
(?:\r?\n|$) # End of line
)
)
| # Or
#################################### Rule 2 ####################################
\G(?<!^) # Preceding contiguous match (not beginning of line)
[^'] # Match anything that not a single quote
(?= # Lookahead to make sure there is an odd number of single quotes ahead
(?: # non-capturing group
(?: # non-capturing group
[^'\r\n]* # Match anything that not a single quote or newline, zero or more times
' # Match a single quote
){2} # Repeat 2 times (We'll be matching 2 single quotes)
)* # Repeat all this zero or more times. So we match 0, 2, 4, 6 ... single quotes
(?:
[^'\r\n]* # Match anything that not a single quote or newline, zero or more times
' # Match a single quote
[^'\r\n]* # Match anything that not a single quote or newline, zero or more times
(?:\r?\n|$) # End of line
)
)
| # Or
#################################### Rule 3 ####################################
\G(?<!^) # Preceding contiguous match (not beginning of line)
' # Match a single quote
~x
Демо-версия онлайн-регге.
Онлайн-демонстрация PHP
Ответ 3
Ну, просто для удовольствия, и я серьезно не рекомендовал бы что-то подобное, потому что я стараюсь избегать поисков, когда они не нужны, здесь одно регулярное выражение, использующее концепцию "назад в будущее":
(?<=^|\s)'(?!\s)|(?!^)(?<!'(?=\s))\G.
демо-версия regex101
Хорошо, он разбит на две части:
1. Соответствие начальной одиночной кавычки
(?<=^|\s)'(?!\s)
Правила, которые, я считаю, должны быть установлены здесь:
- До начала цитаты должно быть либо
^, либо \s (следовательно, (?<=^|\s)).
- После начальной цитаты нет
\s (следовательно, (?!\s)).
2. Сопоставление вещей внутри цитаты и окончательная цитата
(?!^)\G(?<!'(?=\s)).
Правила, которые, я считаю, должны быть установлены здесь:
- Символом может быть любой символ (следовательно,
.)
- Матч длится 1 символ и после немедленного предыдущего совпадения (следовательно
(?!^)\G).
- Не должно быть ни одной кавычки, за которой следует пробел, а перед ним (следовательно,
(?<!'(?=\s)) и это часть "назад в будущее" ). Это фактически не будет соответствовать \s, которому предшествует ', и будет отмечать конец символов, заключенных между одинарными кавычками. Другими словами, заключительная цитата будет обозначена как одиночная кавычка, за которой следует \s.
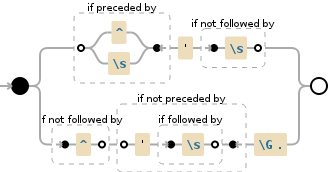
Если вы предпочитаете фотографии...
![img]()