Ответ 1
Извините, я не смог воспроизвести ваш код именно на GCC (linux), но у меня есть некоторые результаты, и я думаю, что основная идея была сохранена в моем коде.
Существует инструмент от Intel для анализа производительности фрагмента кода: http://software.intel.com/en-us/articles/intel-architecture-code-analyzer/ (Intel IACA). Его можно загрузить и протестировать.
В моем эксперименте отчет для медленного цикла:
Intel(R) Architecture Code Analyzer Version - 2.0.1
Analyzed File - ./l2_i
Binary Format - 32Bit
Architecture - SNB
Analysis Type - Throughput
Throughput Analysis Report
--------------------------
Block Throughput: 3.05 Cycles Throughput Bottleneck: Port5
Port Binding In Cycles Per Iteration:
-------------------------------------------------------------------------
| Port | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 |
-------------------------------------------------------------------------
| Cycles | 0.5 0.0 | 0.5 | 1.0 1.0 | 1.0 1.0 | 0.0 | 3.0 |
-------------------------------------------------------------------------
N - port number or number of cycles resource conflict caused delay, DV - Divide
D - Data fetch pipe (on ports 2 and 3), CP - on a critical path
F - Macro Fusion with the previous instruction occurred
| Num Of | Ports pressure in cycles | |
| Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | |
---------------------------------------------------------------------
| 1 | | | | | | 1.0 | CP | cmp edi,
| 0F | | | | | | | | jz 0xb
| 1 | | | 1.0 1.0 | | | | | movzx ebx
| 2 | | | | 1.0 1.0 | | 1.0 | CP | cmp cl, b
| 0F | | | | | | | | jz 0x3
| 1 | 0.5 | 0.5 | | | | | | inc edi
| 1 | | | | | | 1.0 | CP | jmp 0xfff
Для быстрого цикла:
Throughput Analysis Report
--------------------------
Block Throughput: 2.00 Cycles Throughput Bottleneck: Port5
Port Binding In Cycles Per Iteration:
-------------------------------------------------------------------------
| Port | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 |
-------------------------------------------------------------------------
| Cycles | 0.5 0.0 | 0.5 | 1.0 1.0 | 1.0 1.0 | 0.0 | 2.0 |
-------------------------------------------------------------------------
N - port number or number of cycles resource conflict caused delay, DV - Divide
D - Data fetch pipe (on ports 2 and 3), CP - on a critical path
F - Macro Fusion with the previous instruction occurred
| Num Of | Ports pressure in cycles | |
| Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | |
---------------------------------------------------------------------
| 1 | 0.5 | 0.5 | | | | | | inc edi
| 1 | | | | | | 1.0 | CP | cmp edi,
| 0F | | | | | | | | jz 0x8
| 1 | | | 1.0 1.0 | | | | | movzx ebx
| 2 | | | | 1.0 1.0 | | 1.0 | CP | cmp cl, b
| 0F | | | | | | | | jnz 0xfff
Таким образом, в медленном цикле JMP является дополнительной инструкцией в Critical Path. Все пары cmp + jz/jnz объединяются (Macro-fusion) в один u-op. И в моей реализации кода критическим ресурсом является Port5, который может выполнять ALU + JMP (и это единственный порт с возможностью JMP).
PS: Если кто-то не знает, где расположены порты, есть фотографии сначала второй; и статья: rwt
{kind=link}
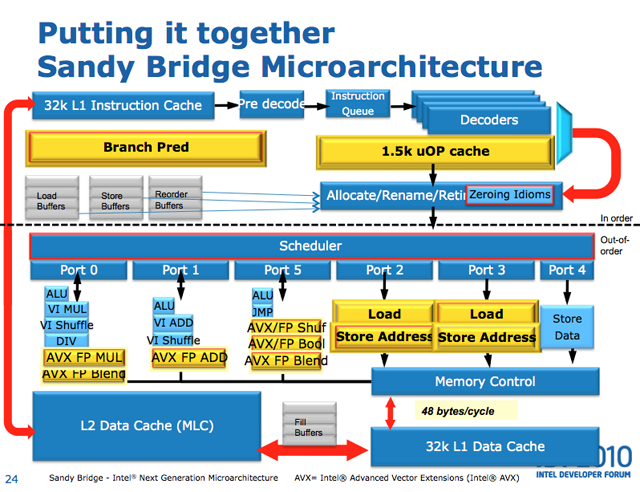{kind=link}
PPS: IACA имеет некоторые ограничения; он моделирует только часть процессора (единицы исполнения) и не пропускает кеширование учетной записи, неверные предсказания веток, различные штрафы, изменения частоты/мощности, прерывания ОС, конкуренцию HyperThreading для единиц исполнения и многие другие эффекты. Но это полезный инструмент, потому что он может дать вам быстрый взгляд в самом внутреннем ядре современного процессора Intel. И он работает только для внутренних циклов (как и петли в этом вопросе).