Ответ 1
Вот ваше регулярное выражение:
(AAA\r\n)(ABC[0-9]\r\n){1,}
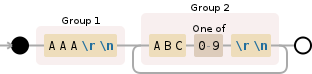
Ваша цель - захватить все ABC#, которые немедленно следуют за AAA. Как вы можете видеть в этой демоверсии Debuggex, все ABC# действительно совпадают (они выделены желтым цветом). Однако, поскольку только часть "что повторяется"
ABC[0-9]\r\n
находится захвачен (находится в круглых скобках) и его quantifier,
{1,}
не записывается, поэтому он вызывает все совпадения, кроме последнего, который должен быть отброшен. Чтобы получить их, вы также должны захватить квантификатор:
AAA\r\n((?:ABC[0-9]\r\n){1,})
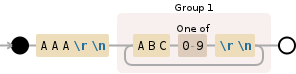
Я поместил часть "то, что повторяется" (ABC[0-9]\r\n) в группу non-captureing. (Я также остановил захват AAA, поскольку вам это не кажется нужным.)
Захваченный текст можно разделить на новую строку и предоставить вам все фрагменты по вашему желанию.
(Обратите внимание, что \n сам по себе не работает в Debuggex, для этого требуется \r\n.)
Это обходной путь. Не многие ароматы регулярных выражений предлагают возможность повторения с помощью повторных захватов (какие из них...?). Более обычным подходом является цикл и обработка каждого совпадения по мере их нахождения. Вот пример из Java:
import java.util.regex.*;
public class RepeatingCaptureGroupsDemo {
public static void main(String[] args) {
String input = "I have a cat, but I like my dog better.";
Pattern p = Pattern.compile("(mouse|cat|dog|wolf|bear|human)");
Matcher m = p.matcher(input);
while (m.find()) {
System.out.println(m.group());
}
}
}
Выход:
cat
dog
(От http://ocpsoft.org/opensource/guide-to-regular-expressions-in-java-part-1/, примерно на 1/4 вниз)
Пожалуйста, рассмотрите возможность закладки часто задаваемых вопросов о регулярных выражениях стека для дальнейшего использования. Ссылки в этом ответе взяты из него.