Сжатие видео: что такое дискретное косинусное преобразование?
Я реализовал технологию преобразования изображения/видео, называемую дискретным косинусным преобразованием. Этот метод используется в кодировании MPEG-видео. Я основывал свой алгоритм на идеях, представленных по следующему URL-адресу:
http://vsr.informatik.tu-chemnitz.de/~jan/MPEG/HTML/mpeg_tech.html
Теперь я могу преобразовать раздел 8x8 черно-белого изображения, например:
0140 0124 0124 0132 0130 0139 0102 0088
0140 0123 0126 0132 0134 0134 0088 0117
0143 0126 0126 0133 0134 0138 0081 0082
0148 0126 0128 0136 0137 0134 0079 0130
0147 0128 0126 0137 0138 0145 0132 0144
0147 0131 0123 0138 0137 0140 0145 0137
0142 0135 0122 0137 0140 0138 0143 0112
0140 0138 0125 0137 0140 0140 0148 0143
В это изображение со всей важной информацией в правом верхнем углу. Преобразованный блок выглядит следующим образом:
1041 0039 -023 0044 0027 0000 0021 -019
-050 0044 -029 0000 0009 -014 0032 -010
0000 0000 0000 0000 -018 0010 -017 0000
0014 -019 0010 0000 0000 0016 -012 0000
0010 -010 0000 0000 0000 0000 0000 0000
-016 0021 -014 0010 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 -010 0013 -014 0010 0000 0000
Теперь, мне нужно знать, как я могу воспользоваться этим преобразованием? Я хотел бы обнаружить другие 8x8 блоков в одном и том же изображении (или другом изображении), которые представляют хорошее совпадение.
Кроме того, что мне дает такое преобразование? Почему важна информация, хранящаяся в правом верхнем углу преобразованного изображения?
Ответы
Ответ 1
Результат DCT - это преобразование исходного источника в частотную область. Верхний левый вход сохраняет "амплитуду", "базовую" частоту и частоту увеличивают как по горизонтальной, так и по вертикальной оси. Результатом DCT обычно является совокупность амплитуд на более обычных низких частотах (верхний левый квадрант) и меньше записей на более высоких частотах. Как упоминал Лассевк, обычно просто обнулять эти более высокие частоты, поскольку они обычно составляют очень незначительные части источника. Однако это приводит к потере информации. Для завершения сжатия обычно используется сжатие без потерь по источнику DCT'd. Здесь происходит сжатие, так как все эти пробеги нулей упаковываются почти до нуля.
Одним из возможных преимуществ использования DCT для поиска похожих регионов является то, что вы можете выполнить совпадение первого прохода по низкочастотным значениям (верхний левый угол). Это уменьшает количество значений, которые необходимо сопоставить. Если вы найдете совпадения низкочастотных значений, вы можете увеличить сравнение более высоких частот.
Надеюсь, что это поможет
Ответ 2
Я узнал все, что знаю о DCT, из Книга сжатия данных. В дополнение к тому, чтобы стать отличным введением в область сжатия данных, у него есть глава ближе к концу о сжатии изображения с потерями, в котором представлены JPEG и DCT.
Ответ 3
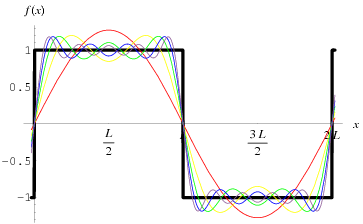
Понятия, лежащие в основе этих преобразований, легче увидеть, посмотрев сначала на одномерный случай. Изображение здесь показывает прямоугольную волну вместе с несколькими из первых членов бесконечной серии. Посмотрев на это, обратите внимание, что если функции для членов складываются вместе, они начинают приближаться к форме прямоугольной волны. Чем больше терминов вы добавляете, тем лучше аппроксимация. Но, чтобы перейти от приближения к точному сигналу, вы должны суммировать бесконечное количество терминов. Причиной этого является то, что квадратная волна является разрывной. Если вы думаете о прямоугольной волне как функции времени, она идет от -1 до 1 в нулевое время. Для представления такой вещи требуется бесконечная серия. Посмотрите еще раз на сюжет серии. Первый - красный, второй - желтый. У последовательных терминов больше переходов "вверх и вниз". Это связано с увеличением частоты каждого термина. Приклеивание квадратной волны как функции времени, а каждый член ряда - функция частоты, существуют два эквивалентных представления: функция времени и функция частоты (1/время).
В реальном мире нет прямоугольных волн. Ничего не происходит в нулевое время. Звуковые сигналы, например, занимают диапазон от 20 Гц до 20 кГц, где Гц - 1 раз. Такие вещи могут быть представлены конечными рядами.
Для изображений математика одна и та же, но две вещи разные. Во-первых, он двумерный. Во-вторых, понятие времени не имеет смысла. В смысле 1D квадратная волна - это просто функция, которая дает некоторое числовое значение для аргумента, который, как мы говорили, был временем. Статическое изображение - это функция, которая дает числовое значение для каждой пары строк, индексов столбцов. Другими словами, изображение является функцией двумерного пространства, являющегося прямоугольной областью. Подобную функцию можно представить в терминах ее пространственной частоты. Чтобы понять, что такое пространственная частота, рассмотрите 8-битное изображение уровня серого и пару соседних пикселей. Самый резкий переход, который может произойти в изображении, идет от 0 (например, черного) до 255 (скажем, белого) на расстоянии 1 пиксель. Это напрямую соответствует наивысшей частоте (последнему) члену серийного представления.
Двумерное преобразование Фурье (или Косинуса) изображения приводит к тому, что массив значений того же размера, что и изображение, представляет ту же информацию не как функцию пространства, а функцию 1/пробела. Информация упорядочивается от самой низкой до самой высокой частоты по диагонали от наивысшей строки начала и столбца. Пример здесь.
Для сжатия изображения вы можете преобразовать изображение, отбросить некоторое количество более высоких частотных терминов и обратное преобразовать оставшиеся обратно в изображение, которое имеет меньше деталей, чем оригинал. Хотя он преобразуется обратно к изображению того же размера (при замене замененных слов на ноль), в частотной области он занимает меньше места.
Другой способ взглянуть на это - уменьшить изображение до меньшего размера. Если, например, вы пытаетесь уменьшить размер изображения, выбрасывая три из каждых четырех пикселей подряд, и три из каждых четырех строк, у вас будет массив размером 1/4, но изображение будет выглядеть ужасно. В большинстве случаев это достигается с помощью 2D-интерполятора, который создает новые пиксели путем усреднения прямоугольных групп больших пикселей изображения. При этом интерполяция имеет эффект, аналогичный отбрасыванию ряда терминов в частотной области, только намного быстрее для вычисления.
Чтобы сделать больше, я приведу пример преобразования Фурье. Любое хорошее обсуждение темы покажет, как связаны преобразования Фурье и Косина. Преобразование Фурье изображения нельзя рассматривать непосредственно как таковое, потому что оно выполнено из комплексных чисел. Он уже разделен на два вида информации: Реальные и мнимые части чисел. Как правило, вы увидите изображения или графики. Но более значимо (обычно) отделить комплексные числа от их величины и угла фазы. Это просто принимает комплексное число на комплексной плоскости и переключается на полярные координаты.
Для аудиосигнала подумайте о комбинированных функциях sin и косинуса, принимающих в своих аргументах количество, необходимое для смещения функции вперед и назад (как часть представления сигнала). Для изображения информация о фазе описывает, как каждый член ряда смещается относительно других членов в частотном пространстве. В изображениях края (надеюсь) настолько отличаются, что они хорошо характеризуются наименьшими частотными членами в частотной области. Это происходит не потому, что они являются резкими переходами, а потому, что они имеют, например, много черной области, прилегающей к много более легкой области. Рассмотрим одномерный срез ребра. Уровень серого равен нулю, затем переходит вверх и остается там. Визуализируйте синусоидальную волну, которая будет первым приближением, где она пересекает среднюю точку перехода сигнала при sin (0). Фазовый угол этого члена соответствует смещению в пространстве изображения. Огромная иллюстрация этого доступна здесь. Если вы пытаетесь найти фигуры и можете создать ссылочную форму, это один из способов их распознавания.
Ответ 4
Если я правильно помню, эта матрица позволяет вам сохранять данные в файл со сжатием.
Если вы читаете дальше вниз, вы увидите, что шаблон zig-zag данных считывается из этой окончательной матрицы. Самые важные данные находятся в верхнем левом углу и наименее важны в нижнем правом углу. Таким образом, если вы перестанете писать в какой-то момент и просто считаете остальное как 0, даже если это не так, вы получите потерю приближения изображения.
Количество выбрасываемых значений увеличивает сжатие за счет точности воспроизведения.
Но я уверен, что кто-то еще может дать вам лучшее объяснение.
Ответ 5
Я бы рекомендовал собрать копию Digital Video Compression - это действительно хороший обзор алгоритмов сжатия изображений и видео.
Ответ 6
Ответ Anthony Cramp выглядел хорошо для меня. Как он упоминает, DCT преобразует данные в частотную область. DCT сильно используется при сжатии видео, поскольку человеческая визуальная система должна быть менее чувствительной к высокочастотным изменениям, поэтому обнуление более высоких значений частоты приводит к уменьшению файла, что мало влияет на восприятие человеком качества видео.
С точки зрения использования DCT для сравнения изображений, я полагаю, что единственным реальным преимуществом является то, что вы отрезаете более высокочастотные данные и, следовательно, имеете меньший набор данных для поиска/сопоставления. Что-то вроде вейвлетов Харра может дать лучшие результаты сопоставления изображений.
{kind=link}
{kind=link}