Почему git нажимал столько данных?
Мне интересно, что делает git, когда он подталкивает изменения и почему кажется, что время от времени выводит больше данных, чем изменения, которые я сделал. Я внес некоторые изменения в два файла, которые добавили около 100 строк кода - менее 2 тыс. Текста.
Когда я отправил данные до начала координат, git превратил это в более чем 47 мб данных:
git push -u origin foo
Counting objects: 9195, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (6624/6624), done.
Writing objects: 100% (9195/9195), 47.08 MiB | 1.15 MiB/s, done.
Total 9195 (delta 5411), reused 6059 (delta 2357)
remote: Analyzing objects... (9195/9195) (50599 ms)
remote: Storing packfile... done (5560 ms)
remote: Storing index... done (15597 ms)
To <<redacted>>
* [new branch] foo -> foo
Branch foo set up to track remote branch foo from origin.
Когда я меняю свои изменения, (origin/master..HEAD), только два файла и одна фиксация, которую я обнаружил. Откуда взялось 47 мб данных?
Я видел это: Когда я делаю "git push" , что означает статистика? (Итого, дельта и т.д.)
и это: Предскажите, сколько данных будет нажато в git push
но это на самом деле не рассказывало мне, что происходит... Почему пакет/пакет огромны?
Ответы
Ответ 1
Я только что понял, что есть очень реалистичный сценарий, который может привести к необычайно большому толчку.
Какие объекты push отправляет? Которые еще не существуют на сервере. Или, скорее, который он не обнаружил как существующий. Как он проверяет существование объекта? В начале push, сервер отправляет ссылки (ветки и теги), которые есть. Так, например, если у них есть следующие коммиты:
CLIENT SERVER
(foo) -----------> aaaaa1
|
(origin/master) -> aaaaa0 (master) -> aaaaa0
| |
... ...
Затем клиент получит что-то вроде /refs/heads/master aaaaa0 и обнаружит, что он должен отправлять только то, что является новым в commit aaaaa1.
Но, если кто-то что-то выдвинул на удаленный мастер, это другое:
CLIENT SERVER
(foo) -----------> aaaaa1 (master) --> aaaaa2
| /
(origin/master) -> aaaaa0 aaaaa0
| |
... ...
Здесь клиент получает refs/heads/master aaaaa2, но он ничего не знает о aaaaa2, поэтому он не может сделать вывод, что aaaaa0 существует на сервере. Таким образом, в этом простом случае только 2 веток будет отправлена вся история, а не только инкрементная.
Это вряд ли произойдет во взрослом, активно развивающемся проекте, в котором есть теги и множество веток, некоторые из которых устарели и не обновляются. Таким образом, пользователи могут посылать немного больше, но это не становится такой большой разницей, как в вашем случае, и остается незапятнанным. Но в очень маленьких командах это может случаться чаще, и разница будет значительной.
Чтобы избежать этого, вы можете запустить git fetch перед push. Тогда, в моем примере, aaaaa2 уже существует на клиенте, и git push foo будет знать, что он не должен отправлять aaaaa0 и более старую историю.
Читайте здесь для реализации push в протоколе.
PS: недавняя функция git commit graph могла бы помочь с этим, но я не пробовал.
Ответ 2
Когда я отправил данные до начала координат, git превратил это в более чем 47 Мб данных.
Похоже, ваш репозиторий содержит много данных двоичных файлов.
Сначала посмотрим, что делает git push?
git-push - обновить удаленные ссылки ref вместе со связанными объектами
Что это за associated objects?
После каждой фиксации вы выполняете git выполнение pack ваших данных в файлы с именем
XX.pack && `XX.idx '
Хорошее чтение о упаковке здесь
![введите описание изображения здесь]()
Как git упаковывать файлы?
Формат упакованного архива .pack предназначен для автономной работы, поэтому его можно распаковать без дополнительной информации.
Поэтому каждый объект, от которого зависит треугольник, должен присутствовать в пакете.
Создается пакетный индексный файл .idx для быстрого и произвольного доступа к объектам в пакете.
Размещение индексного файла .idx и упакованного архива .pack в подкаталоге pack $GIT_OBJECT_DIRECTORY (или любой из каталогов на $GIT_ALTERNATE_OBJECT_DIRECTORIES) позволяет git читать из архива пакетов.
Когда git упаковывает ваши файлы, он делает это разумно, поэтому для извлечения данных будет очень быстро.
Для достижения этого git используйте pack-heuristics, который в основном ищет подобную часть контента в вашем пакете и сохраняет их как единый, то есть - если у вас есть один и тот же заголовок (например, лицензионное соглашение) во многих файлах, git "найдет" его и сохранит его один раз.
Теперь все файлы, которые включают эту лицензию, будут содержать указатель в коде заголовка. В этом случае git не нужно хранить один и тот же код снова и снова, поэтому размер пакета минимален.
Это одна из причин, почему это не очень хорошая идея, и не рекомендуется хранить двоичные файлы в git, так как вероятность сходства очень низкая, поэтому размер пакета не будет оптимальным.
Git сохраняйте свои данные в зашифрованном формате, чтобы уменьшить пространство, поэтому двоичный файл не будет оптимальным, а также zip (размер wize).
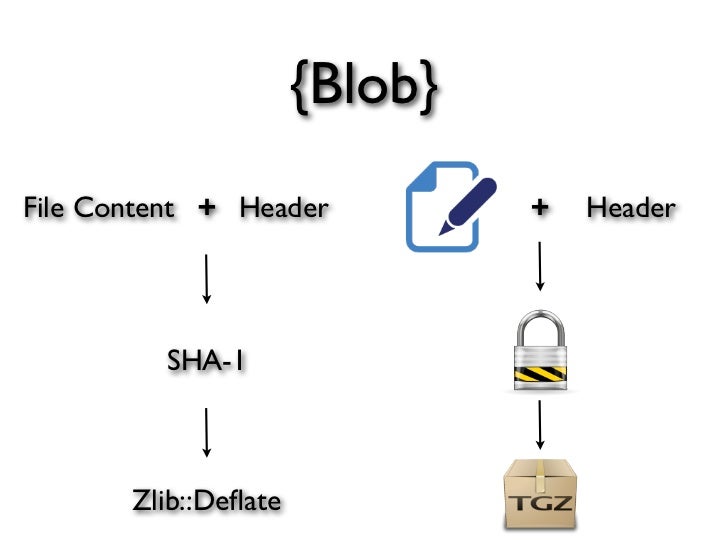
Вот образец git blob с использованием сжатого сжатия:
![введите описание изображения здесь]()