Оптимальный исполняемый запрос для последней записи для каждого N
Вот сценарий, в который я оказался.
У меня есть достаточно большая таблица, в которой мне нужно запрашивать последние записи. Вот создание необходимых столбцов для запроса:
CREATE TABLE [dbo].[ChannelValue](
[ID] [bigint] IDENTITY(1,1) NOT NULL,
[UpdateRecord] [bit] NOT NULL,
[VehicleID] [int] NOT NULL,
[UnitID] [int] NOT NULL,
[RecordInsert] [datetime] NOT NULL,
[TimeStamp] [datetime] NOT NULL
) ON [PRIMARY]
GO
Идентификационный столбец является Первичным ключом и есть некластеризованный индекс для VehicleID и TimeStamp
CREATE NONCLUSTERED INDEX [IX_ChannelValue_TimeStamp_VehicleID] ON [dbo].[ChannelValue]
(
[TimeStamp] ASC,
[VehicleID] ASC
)ON [PRIMARY]
GO
В таблице, над которой я работаю, для оптимизации моего запроса используется чуть более 23 миллионов строк, это всего лишь 10-й размер, с которым должен работать запрос.
Мне нужно вернуть последнюю строку для каждого идентификатора VehicleID.
Я просматривал ответы на этот вопрос здесь, в StackOverflow, и я сделал справедливый бит Googling, и, похоже, есть 3 или 4 общих способа сделать это на SQL Server 2005 и выше.
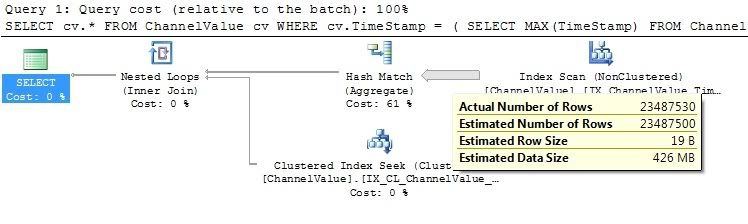
До сих пор самым быстрым методом, который я нашел, является следующий запрос:
SELECT cv.*
FROM ChannelValue cv
WHERE cv.TimeStamp = (
SELECT
MAX(TimeStamp)
FROM ChannelValue
WHERE ChannelValue.VehicleID = cv.VehicleID
)
При текущем количестве данных в таблице требуется около 6 секунд для выполнения, что находится в разумных пределах, но с объемом данных, которые таблица будет содержать в живой среде, запрос начинает выполнять слишком медленно.
Глядя на план выполнения, я беспокоюсь о том, что делает SQL Server для возврата строк.
Я не могу опубликовать образ плана выполнения, потому что моя репутация недостаточно высока, но сканирование индекса анализирует каждую строку внутри таблицы, которая так сильно замедляет запрос.
![Execution Plan]()
Я попытался переписать запрос несколькими различными методами, включая метод SQL Server Partition следующим образом:
WITH cte
AS (
SELECT *,
ROW_NUMBER() OVER(PARTITION BY VehicleID ORDER BY TimeStamp DESC) AS seq
FROM ChannelValue
)
SELECT
VehicleID,
TimeStamp,
Col1
FROM cte
WHERE seq = 1
Но производительность этого запроса еще хуже по довольно большой величине.
Я попытался реструктурировать такой запрос, но скорость выполнения результатов и план выполнения запросов почти идентичны:
SELECT cv.*
FROM (
SELECT VehicleID
,MAX(TimeStamp) AS [TimeStamp]
FROM ChannelValue
GROUP BY VehicleID
) AS [q]
INNER JOIN ChannelValue cv
ON cv.VehicleID = q.VehicleID
AND cv.TimeStamp = q.TimeStamp
У меня есть гибкость, доступная мне вокруг структуры таблицы (хотя и в ограниченной степени), поэтому я могу добавлять индексы, индексированные представления и т.д. или даже дополнительные таблицы в базу данных.
Я был бы очень признателен за любую помощь здесь.
Редактировать Добавлена ссылка на образ плана выполнения.
Ответы
Ответ 1
Зависит от ваших данных (сколько строк на каждой группе?) и ваших индексов.
См. Оптимизация TOP N на групповые запросы для сравнения производительности трех подходов.
В вашем случае с миллионами строк только для небольшого количества транспортных средств я бы добавил индекс на VehicleID, Timestamp и сделал
SELECT CA.*
FROM Vehicles V
CROSS APPLY (SELECT TOP 1 *
FROM ChannelValue CV
WHERE CV.VehicleID = V.VehicleID
ORDER BY TimeStamp DESC) CA
Ответ 2
Если ваши записи вставляются последовательно, замена TimeStamp в вашем запросе с помощью ID может иметь значение.
Как примечание, сколько записей это возвращается? Задержка может быть накладной, если вы вернете сотни тысяч строк.
Ответ 3
Попробуйте следующее:
SELECT SequencedChannelValue.* -- Specify only the columns you need, exclude the SequencedChannelValue
FROM
(
SELECT
ChannelValue.*, -- Specify only the columns you need
SeqValue = ROW_NUMBER() OVER(PARTITION BY VehicleID ORDER BY TimeStamp DESC)
FROM ChannelValue
) AS SequencedChannelValue
WHERE SequencedChannelValue.SeqValue = 1
Ожидается сканирование таблиц или индексов, поскольку вы никоим образом не фильтруете данные. Вы запрашиваете последний TimeStamp для всех идентификаторов VehicleID - механизм запросов. Посмотрите на каждую строку, чтобы найти последний TimeStamp.
Вы можете помочь, сужая количество возвращаемых столбцов (не используйте SELECT *) и предоставляя индекс, который состоит из VehicleID + TimeStamp.