Что такое num_units в tensorflow BasicLSTMCell?
В примерах MNIST LSTM я не понимаю, что означает "скрытый слой". Это сформированный воображаемый слой, когда вы представляете развернутый RNN со временем?
Почему в большинстве случаев num_units = 128?
Я знаю, что я должен подробно прочитать блог колы, чтобы понять это, но до этого я просто хочу получить код, работающий с данными временного ряда, которые у меня есть.
Ответы
Ответ 1
Количество скрытых единиц является прямым представлением учебной способности нейронной сети - оно отражает количество изученных параметров. Значение 128, вероятно, было выбрано произвольно или эмпирически. Вы можете изменить это значение экспериментально и повторно запустить программу, чтобы увидеть, как она влияет на точность обучения (вы можете получить более 90% точности теста с гораздо меньшим количеством скрытых единиц). Использование большего количества единиц делает более вероятным полное запоминание полного набора тренировок (хотя это займет больше времени, и вы рискуете переустановить).
Ключевое значение для понимания, которое несколько тонко в знаменитом сообщении в блоге Colah (найти "каждая строка несет целый вектор" ), заключается в том, что X представляет собой массив данных (в настоящее время часто называемый tensor) - это не означает скалярное значение. Где, например, показана функция tanh, она подразумевает, что функция передается по всему массиву (неявный цикл for) - и не просто выполняется один раз для шага времени.
Таким образом, скрытые единицы представляют собой ощутимое хранилище в сети, которое проявляется прежде всего в размере массива весов. И поскольку LSTM на самом деле имеет немного своего собственного внутреннего хранилища отдельно от изученных параметров модели, он должен знать, сколько единиц есть, что в конечном итоге должно согласовываться с размером весов. В простейшем случае RNN не имеет внутреннего хранилища - поэтому ему даже не нужно заранее знать, сколько "скрытых единиц" оно применяется.
- Хороший ответ на аналогичный вопрос здесь.
- Вы можете посмотреть источник для BasicLSTMCell в TensorFlow, чтобы узнать, как именно это используется.
Боковое примечание: Эта нотация очень распространена в статистике и машинном обучении, а также в других областях, которые обрабатывают большие партии данных с помощью общей формулы (3D-графика - еще один пример). Требуется немного привыкнуть к тем, кто ожидает, что их циклы for выписаны явно.
Ответ 2
Из этой блестящей статьи
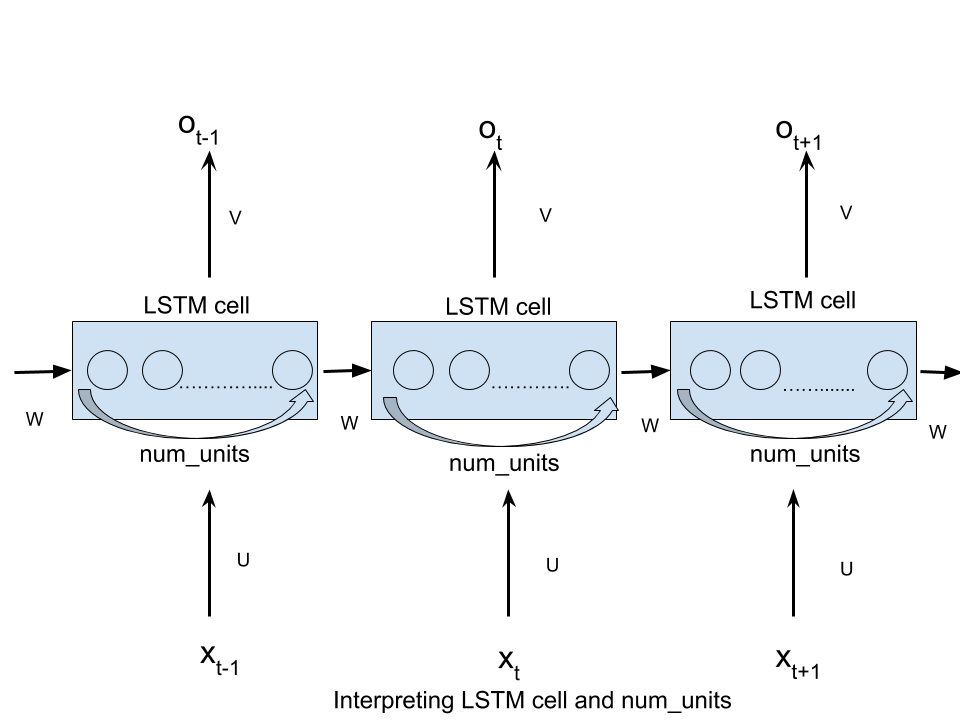
num_units можно интерпретировать как аналог скрытого слоя от нейронной сети с прямой связью. Число узлов в скрытом слое нейронной сети с прямой связью эквивалентно числу num_units единиц LSTM в ячейке LSTM на каждом временном шаге сети.
Смотрите изображение там тоже!
![enter image description here]()
Ответ 3
Аргумент n_hidden of BasicLSTMCell - это количество скрытых единиц LSTM.
Как вы сказали, вы действительно должны прочитать сообщение Cola в блоге, чтобы понять LSTM, но вот немного хедз-ап.
Если у вас есть вход x формы [T, 10], вы будете подавать LSTM с последовательностью значений от t=0 до t=T-1, каждый из которых имеет размер 10.
В каждом временном значении вы умножаете вход с матрицей формы [10, n_hidden] и получаете вектор n_hidden.
Ваш LSTM получает каждый таймepep t:
- предыдущее скрытое состояние
h_{t-1}, размер n_hidden (при t=0, предыдущее состояние [0., 0., ...])
- ввод, преобразованный в размер
n_hidden
- он будет суммировать эти входы и вывести следующее скрытое состояние
h_t размера n_hidden
Из сообщения блога Colah:
![LSTM]()
Если вы просто хотите работать с кодом, просто держитесь с n_hidden = 128, и все будет в порядке.
Ответ 4
LSTM хранит две части информации по мере ее распространения:
hidden состояние; которая является памятью, которую LSTM накапливает, используя свои (forget, input, and output) затворы во времени и предыдущий выход с временным шагом.
Tensorflows num_units - это размер скрытого состояния LSTM (который также является размером вывода, если не используется проекция).
Чтобы сделать имя num_units более интуитивно понятным, вы можете думать о нем как о количестве скрытых единиц в ячейке LSTM или количестве единиц памяти в ячейке.
Посмотрите на этот удивительный пост для большей ясности
Ответ 5
Я думаю, что это запутывает для пользователей TF термин "num_hidden". На самом деле это не имеет ничего общего с развернутыми ячейками LSTM, и это просто размер тензора, который преобразуется из тензора входного сигнала времени и подается в ячейку LSTM.
Ответ 6
Этот термин num_units или num_hidden_units иногда отмечаемый с использованием имени переменной nhid в реализациях, означает, что вход в ячейку LSTM представляет собой вектор измерения nhid (или для пакетной реализации это будет матрица формы batch_size x nhid). В результате выход (из ячейки LSTM) также будет иметь такую же размерность, поскольку ячейка RNN/LSTM/GRU не изменяет размерность входного вектора или матрицы.
Как указывалось ранее, этот термин был заимствован из литературы "Прямые нейронные сети" (FFN) и вызвал путаницу при использовании в контексте RNN. Но идея заключается в том, что даже RNN можно рассматривать как FFN на каждом временном шаге. В этом представлении скрытый слой действительно будет содержать num_hidden как показано на этом рисунке:
![rnn-hidden-units]()
Источник: Понимание LSTM
Более конкретно, в приведенном ниже примере значение num_hidden_units или nhid будет равно 3, поскольку размер скрытого состояния (средний слой) является трехмерным вектором.
![enter image description here]()
Ответ 7
Так как у меня были некоторые проблемы с объединением информации из разных источников, я создал рисунок ниже, который показывает комбинацию поста в блоге (http://colah.github.io/posts/2015-08-Understanding-LSTMs/) и (https://jasdeep06.github.io/posts/Understanding-LSTM-in-Tensorflow-MNIST/), где я думаю, что графика очень полезна, но ошибка в объяснении number_units.
Несколько ячеек LSTM образуют один слой LSTM. Это показано на рисунке ниже. Поскольку вы в основном имеете дело с очень обширными данными, невозможно объединить все в одной части в модель. Поэтому данные делятся на небольшие части как партии, которые обрабатываются одна за другой до тех пор, пока не будет прочитана партия, содержащая последнюю часть. В нижней части рисунка вы можете видеть ввод (темно-серый), где считываются партии один за другим от партии 1 до партии batch_size. Ячейки LSTM от ячейки 1 до ячейки LSTM, описанные выше, представляют описанные ячейки модели LSTM (http://colah.github.io/posts/2015-08-Understanding-LSTMs/). Количество ячеек равно количеству фиксированных временных шагов. Например, если вы берете текстовую последовательность из 150 символов, вы можете разделить ее на 3 (batch_size) и иметь последовательность длиной 50 на пакет (количество time_steps и, следовательно, ячеек LSTM). Если вы затем закодируете каждый символ в горячем виде, каждый элемент (темно-серые поля ввода) будет представлять вектор, который будет иметь длину словаря (количество признаков). Эти векторы будут перетекать в нейронные сети (зеленые элементы в клетках) в соответствующих клетках и изменят свое измерение на длину количества скрытых единиц (number_units). Таким образом, вход имеет размерность (batch_size x time_step x features). Долгосрочная память (состояние ячейки) и Кратковременная память (скрытое состояние) имеют одинаковые размеры (batch_size x number_units). Светло-серые блоки, которые возникают из ячеек, имеют другое измерение, потому что преобразования в нейронных сетях (зеленые элементы) происходили с помощью скрытых единиц (batch_size x time_step x number_units). Выходные данные могут быть возвращены из любой ячейки, но в основном важна только информация из последнего блока (черная граница) (не во всех проблемах), поскольку она содержит всю информацию из предыдущих временных шагов.
![LSTM architecture_new]()
Ответ 8
Большинство диаграмм LSTM/RNN показывают только скрытые ячейки, но не единицы этих ячеек. Отсюда и путаница. Каждый скрытый слой имеет скрытые ячейки, столько же, сколько и количество временных шагов. И далее, каждая скрытая ячейка состоит из нескольких скрытых единиц, как на диаграмме ниже. Следовательно, размерность матрицы скрытого слоя в RNN равна (количество временных шагов, количество скрытых единиц).
![enter image description here]()
Ответ 9
Концепция скрытого устройства иллюстрируется на этом изображении https://imgur.com/Fjx4Zuo.






{kind=link}