Ответ 1
Spark 2.0.0 +
На первый взгляд все Transformers и Estimators реализуют MLWritable. Если вы используете Spark & lt; = 1.6.0 и испытываете некоторые проблемы с сохранением модели, я бы предложил версию переключения.
Искрa >= 1.6
Так как Spark 1.6 можно сохранить ваши модели с помощью метода save. Потому что почти каждый model реализует интерфейс MLWritable. Например, LinearRegressionModel имеет его, и поэтому вы можете сохранить свою модель по желаемому пути, используя ее.
Spark & lt; 1,6
Я считаю, что вы делаете неправильные предположения здесь.
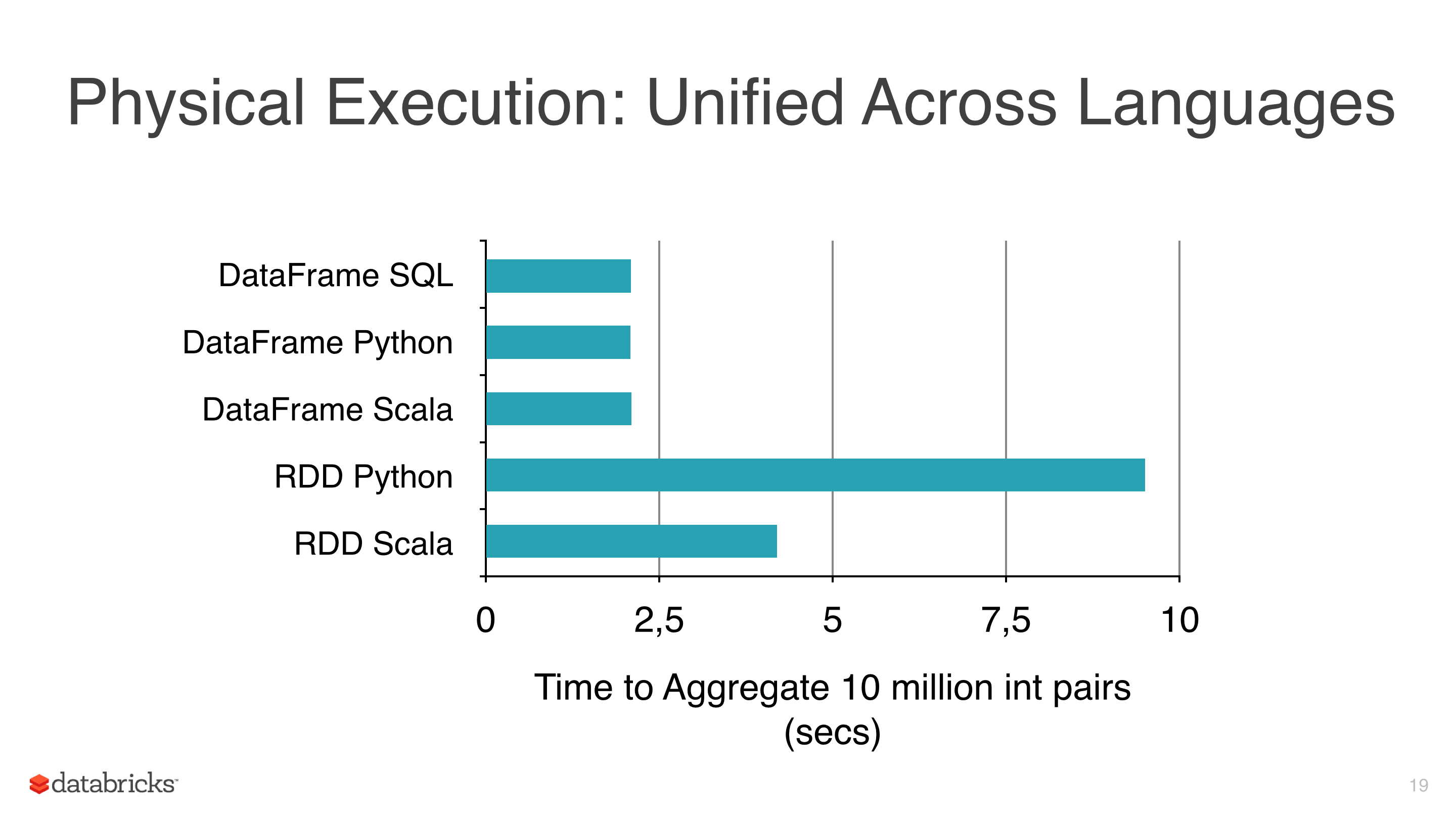
Некоторые операции над DataFrames могут быть оптимизированы, и это приводит к повышению производительности по сравнению с обычным RDDs. DataFrames обеспечивают эффективное кэширование и SQLish API, возможно, легче понять, чем RDD API.
ML Трубопроводы чрезвычайно полезны, и инструменты, такие как кросс-валидатор или разные оценщики, просто должны быть в любом конвейере машины, и даже если ни одно из вышеперечисленных особенно трудно реализовать поверх низкоуровневого MLlib API, гораздо лучше готовы к использованию, универсальное и относительно хорошо протестированное решение.
Пока все хорошо, но есть несколько проблем:
- насколько я могу сказать, что простые операции над
DataFramesпохожими наselectилиwithColumnпоказывают аналогичную производительность с его эквивалентами RDD, такими какmap, - в некоторых случаях увеличение количества столбцов в типичном конвейере может фактически ухудшить производительность по сравнению с хорошо настроенными преобразованиями низкого уровня. Вы можете, конечно, добавить drop-column-transformers на пути исправления для этого,
- многие алгоритмы ML, включая
ml.classification.NaiveBayesявляются просто обертками вокруг своего APImllib, - Алгоритмы PySpark ML/MLlib делегируют фактическую обработку своим Scala аналогам,
- последнее, но не менее важное: RDD по-прежнему существует, даже если он хорошо скрыт за API DataFrame
Я считаю, что в конце концов то, что вы получаете с помощью ML over MLLib, довольно элегантно, API высокого уровня. Единственное, что вы можете сделать, это объединить оба для создания настраиваемого многоэтапного конвейера:
- использовать ML для загрузки, очистки и преобразования данных,
- извлечь необходимые данные (см., например, метод extractLabeledPoints) и перейти к алгоритму
mllib, - добавить пользовательскую перекрестную проверку/оценку
- сохраните модель
mllib, используя метод по вашему выбору (модель Spark или PMML)
Это не оптимальное решение, но лучшее, что я могу придумать для текущего API.